CLOCK:
--->The variations in a local clock edge relative to a master clock reference.
--->The difference between arrival times of the clock at different devices is called skew.
FOR MORE REFERENCE CLICK HERE
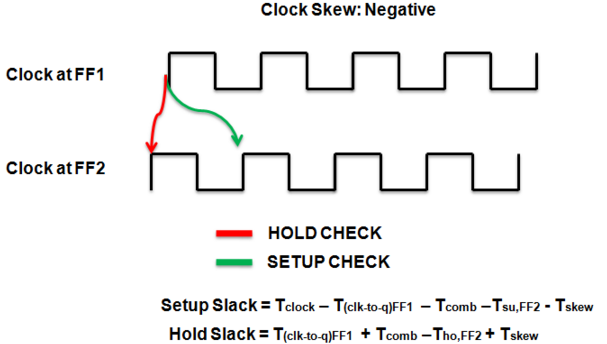
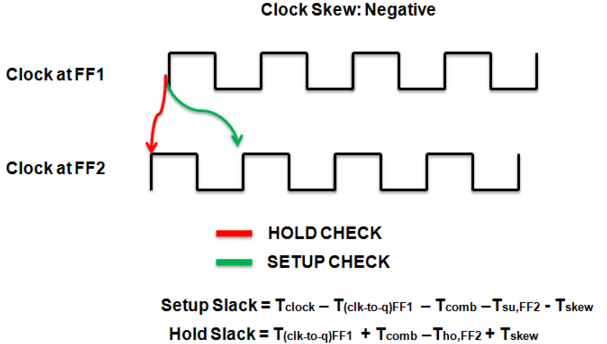
--->The variations in a local clock edge relative to a master clock reference.
--->The difference between arrival times of the clock at different devices is called skew.
FOR MORE REFERENCE CLICK HERE